
Forum Replies Created
-
AuthorPosts
-
David TaurielloKeymaster
Bruno – I was thinking about the ’empty report’ issue you mentioned here again:
“To try it out, I used dts.ids from smaller filers (as opposed to the usual suspects like Apple, Microsoft, etc.). Interestingly enough, once you move into that territory, dts.ids frequently (I would say 9 out of 10) result in no response, for some reason.”
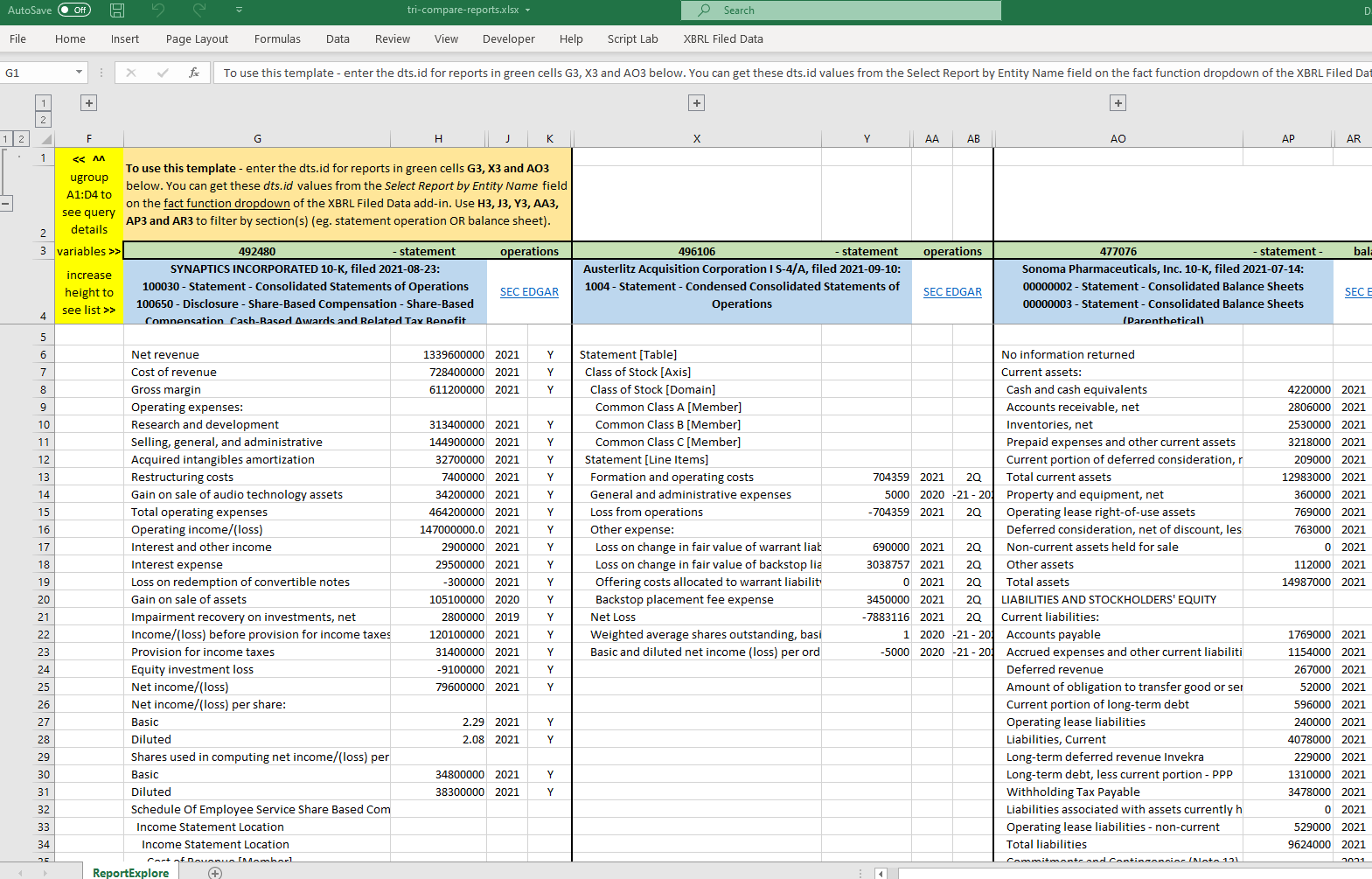
Next time you get a ‘blank’ result on the comparison template:
- clear the green cells to the right of the one that says “-statement” and you should see some data from the report (these cells filter the data from the selected
dts.id). - use the updated details in the blue cell to identify a specific report,
- enter that text (or number) in the cell to the right of “-statement” you just cleared, and you should see details for that section of the report.
Tim BuiParticipantHello Peter Reed and Peter Miller, I am not a programmer (I am learning Python and XML so I can understand Peter Reed’s codes) so I don’t really use the JSON files that the SEC provided in its CompanyFacts zip folder. The way I understand it, we have to define or create our own standardization, depending on the level of detail we want. The SEC only provides the “common name” as shown on the financial statements. Due to my limited programming skills, rather than using the JSON files, currently I download the monthly Financial Statement and Notes Data Set (https://www.sec.gov/dera/data/financial-statement-and-notes-data-set.html) and import those files into Postgresql. However, eventually it seems that I need to learn JSON so I can use those daily JSON files to update data.
Peter W ReedParticipantMy experience is that any json downloads like the one in your posting can be treated like a dictionary. I looked at the page you provided and that’s what I saw was a hierarchical Python dictionary.
I apologize for this next statement – “please don’t take any of the code I’ve provided as anything more than pseudo-code. It is not a final product, and I may choose to drop that line of inquiry and go in a different direction.”
I hit a real dilemma yesterday. I found that knowledge of context (“contextRef”) is required. A 10-K I was parsing I associated common name with a us-gaap tag name. The problem was I found that common name to tag pairing occurred twice for two entries. This can be seen in the Edgar supplied excel file. A human reader can understand the double entries but not a simple software program. The “contextRef” in the XBRL file shows the second pair is part of a segment of the 10-K. The first pair is in the main body (not a segment) of the filing.
Tim BuiParticipantHello Peter Reed (sorry I have to use your last name as well because there are 2 Peters on this discussion),
Could you please elaborate the point ” I found that knowledge of context (“contextRef”) is required”? I am not familiar with “contextRef”. Are you thinking about the debit/credit notation of each of the tag?
Peter W ReedParticipantI thought about your json task. I haven’t tried this command before but I like Pandas as a data structure – pandas.io.json.read_json. This command should load your file into a DataFrame. It is a large file. I don’t know if that will be an issue for you.
On contextRef – In 10-k/Q filings on Edgar there is included a file titled “Extracted XBRL instance document”. Below is a link to a Costco 10-K XBRL file. Below that link is an extract from the XBRL file showing the Document Type (“10-K”). You can see the attributes including the contextRef element. There is a second contextRef in the file, see the second example. The difference between the two is identified by the timeframe – ‘D20190902-20200830’ and ‘I20200929’. The duration is for gaap tags like net sales which accumulates over time 09/02/2019 to 08/30/2020. The instant gaap tag is for attributes like “Assets”. It indicates a snapshot in time of the company’s asset, etc..
https://www.sec.gov/Archives/edgar/data/909832/000090983220000017/cost-20200830_htm.xml
<dei:DocumentType contextRef=”i66090f23f2724bb78bc8f6b7c7081361_D20190902-20200830″ id=”id3VybDovL2R…-0507782e341b”>10-K</dei:DocumentType>
<dei:EntityCommonStockSharesOutstanding contextRef=”i270a3479d6ec49b29cb9fa2ac0b615bb_I20200929″ decimals=”INF” id=”id3VybDovL2R…-97e8-f700a530d6e0″ unitRef=”shares”>441228027</dei:EntityCommonStockSharesOutstanding>
Peter W ReedParticipantI had forgotten that I looked at the data set file before. Here is a code snippet that could help you. dicAcc is a python dictionary.
Note the parameter “headers”. Python url libraries put Python as the user-agent. You need to overwrite that, else Edgar will reject your request. I also remember having problems due to the file sizes. I broke the Edgar data file into five segmented files. At the bottom is the code I used to parse the five files (A,B,C,D). compress[“AAPL”] returns Apple’s cik.Get file-
# Get the accession number to Ticker mapping file from Edgar
targetUrl = “https://www.sec.gov/files/company_tickers.json”
r = requests.get(targetUrl, headers=headers)
dicAcc = r.json()
print(r.status_code)headers = {
“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0”
}Parse file A:
cik = str(compress[‘AAPL’])
aaplLst = []
#
with open(filePathA, “r”) as f:
for line in f:
if re.search(cik, line):
aaplLst.append([line.rstrip().replace(‘\t’,’,’)])Bruno LererParticipantHi, David. I actually was about to respond to your previous message when I saw this one. But I stopped and followed your instructions – and let me tell you: I don’t know what to think anymore…
FYI – to make sure it wasn’t a problem with my own setup, I replicated the whole thing on another computer (same Windows/Excel 365 versions) – with more or less same results. To confuse things more, when I read this new reply, I downloaded yet another, virgin, copy of the compare workbook and tried everything there – now I’m getting different results in each version of the spreadsheet…
Case in point, dts.id 492480: if I plug it in cell W3 (or its siblings G3 and AO3) of the previous version of the sheet, the output in cell W4 is: “SYNAPTICS INCORPORATED 10-K, filed 2021-08-23:”. Doing the exact same thing in the same places in the new, unsullied version of the sheet outputs only ” , filed: “. This outcome obtain regardless of whether or not I “clear the green cells to the right of the one that says “-statement”.
Similar output results from using:
496106 “Austerlitz Acquisition Corporation I S-4/A, filed 2021-09-10:”
477076 “Sonoma Pharmaceuticals, Inc. 10-K, filed 2021-07-14:”
485391 Magnachip Semiconductor Corporation 10-Q, filed 2021-08-06:To make things even more interesting (if that’s the right term), if I open a new worksheet in the same workbook, and enter
=XBRL.showData(CONCATENATE("https://api.xbrl.us/api/v1/fact/search?dts.id=492480&period.fiscal-period=Y&concept.local-name=Assets&fact.has-dimensions=false&fields=concept.local-name,fact.value,period.fiscal-period,dts.id,period.fiscal-year,fact",".limit(),fact.offset()&"),"", "", "1")
the output isn’t empty, it’s:
`concept.local-name fact.value period.fiscal-period dts.id period.fiscal-year
Assets 2226800000 Y 492480 2021
Assets 1693800000 Y 492480 2020Same with the other dts.ids above. And, btw, if I do the same thing in the newly downloaded version of the compare workbook (with the other workbook being closed at the time), the output is “No information returned”.
So, as I said, don’t know what to think anymore…
While I’m at it, can please expand (maybe in a different answer) on the use cells H3 and and J3 (and their siblings)? You mentioned in another answer something about updates to the the relationship query – I suspect these are related but I can’t find any reference that explains how they all works. Specifically, If I’m after a term that appears in both a balance sheet and income statement, it would be useful to be able to limit the search results to one or the other.
Thanks again and sorry for the long post (again).
- This reply was modified 2 years, 7 months ago by Bruno Lerer.
David TaurielloKeymasterHi Bruno – Thanks for the
dts.idvalues. I was unable to replicate the issues you describe with a non-Member test account, so I sent you an appointment to do a quick screen share (I’m guessing something I’ve written about how to use the green cells to filter the report has gotten lost in translation). If the time doesn’t work, please propose a couple of alternatives.
 Bruno LererParticipant
Bruno LererParticipantDavid,
Thanks again for the illuminating mini-tutorial!
For those following – turns out that clearing the offending green cells did solve the problem.Next steps – get the most recent version of the template and pay much more attention to the
relationshipquery…Bruno LererParticipantNow that I’ve been introduced to the joys of the
relationshipquery, I spent some time playing with it in the tri-compare template. With “balance sheet”, etc. searches, things are as expected, but…If you input in cells G3,H3 and I3 (or their siblings) either of the following set of values
443815 ="compensation" 11101 485391 ="leases" 1032 477076 = "tax" 00000022the content of cell H6 (and, depending on the query, H7, H8, etc.) is a full HTML page containing both narrative and related tabular data (“NOTE K – SHARE-BASED COMPENSATION”, for example).
AFAIK, there is no way in Excel to parse the html in that cell (
FILTERXML(), strangely enough, only works with URLs, not with content in the workbook).Is that, as they used to say, a bug or a feature?
- This topic was modified 2 years, 7 months ago by Bruno Lerer.
- This topic was modified 2 years, 7 months ago by Bruno Lerer.
Tuesday, September 21, 2021 at 3:29 PM in reply to: Getting started with the XBRL Google Sheet and add-on #194226Chris MartinezParticipantHi David
Unable to get any Query to work (other than the first one), from the several options available on the Main Sheet (cell B2).
Have carried out the following steps, below, but still not effective:
-erased all old copies of XBRL API sheets
– created a folder for all new copies of API sheets
– cleared cache
-ensured that I am “authorized” to request data
– error message received “unknown function – show data”Unsure how to correct this situation – any suggestions appreciated.
ChrisTuesday, September 21, 2021 at 3:58 PM in reply to: relationship query creates a full html table in output cells #194228David TaurielloKeymasterHi Bruno – you might find or write a VBA macro to handle this, although a disclosure can often run several pages and might be tough to work with.
The XBRL Statements and Disclosures template for Excel (second in the list on the XBRL Data Community) has been recently updated to accommodate HTML – when the
fact.valuecontains HTML, a link appears in the row that opens a browser to the rendered entry in our Public Filings Database.Tuesday, September 21, 2021 at 4:08 PM in reply to: Getting started with the XBRL Google Sheet and add-on #194230David TaurielloKeymasterHi Chris – see https://xbrl.us/forums/topic/api-google-sheet/#troubleshooting – step 3 or 4 should clear your issue (there are two techniques to try in 4 – removing the ‘root’ for the query, and disabling all functions in the sheet for a moment, then re-enabling them.
Thursday, September 23, 2021 at 7:42 PM in reply to: relationship query creates a full html table in output cells #194272Bruno LererParticipantThanks, David.
I don’t know VBA (nor do I have any interest whatsoever in getting to know it…), but from bitter experience in trying to parse EDGAR HTMl documents (with both Python and JavaScript), I know that is a fool’s errand. I guess we’ll have to live with it.
As an aside – regarding the update to the template you mention; I wasn’t aware of the update – it may be a good idea to add to each file in the list of the Member-contributed API Templates and Tools, a field indicating when that file was last updated.
- This reply was modified 2 years, 7 months ago by Bruno Lerer.
Peter W ReedParticipantI believe I found the solution. There are tables for the 10-K/Q reports on Edgar that are not immediately seen using a browser. Below is my description for retrieving the reports. I assume knowledge of web scraping via BeautifulSoup, request.urlopen(), and regex (re). Paste the URL into your browser to see the table. You can use the “inspect” function of the browser to see the parameters to scrape: Here is a summary –
URL for reports:
f”https://www.sec.gov/Archives/edgar/data/{cik}/{accessionNoHyphen}/
{rptNum}.htm”
where:
cik: 0000909832 # With leading zeros removed, e.g. 909832
SEC Accession No.: 0000909832-18-000022
accessionNoHyphen: 000090983218000022
Report Number- rptNum: “R{1-9+}”Scraping this report will yield: (1) Common Name, (2) XBRL tag name, (3) Numerical value for the common name entry, (4) Credit type (debt/credit, (5) Period type – duration or instant, (6) Definition for the XBRL tag.
When I great solid code to share I’ll put it on github. This may take a few weeks.
- This reply was modified 2 years, 7 months ago by Peter W Reed. Reason: URL too long for a single line
- clear the green cells to the right of the one that says “-statement” and you should see some data from the report (these cells filter the data from the selected
-
AuthorPosts





