

XBRL API updates improve AI Connector efficiency
Posted Friday, July 10By David Tauriello, Vice President of Operations, XBRL US
Since the release of the XBRL API in 2018, we've heard from hundreds of users with questions and feedback on functionality to improve analysis with data from our Public Filings Database. We've tightened up the efficiency of XBRL API filters and fields, and even added functionality to enable comparison filtering (between, greater than, less than, etc.) for fact.value and period.fiscal-year parameters. For example, the query below returns extension concepts Microsoft used in reports AFTER (greater than) fiscal year 2023:
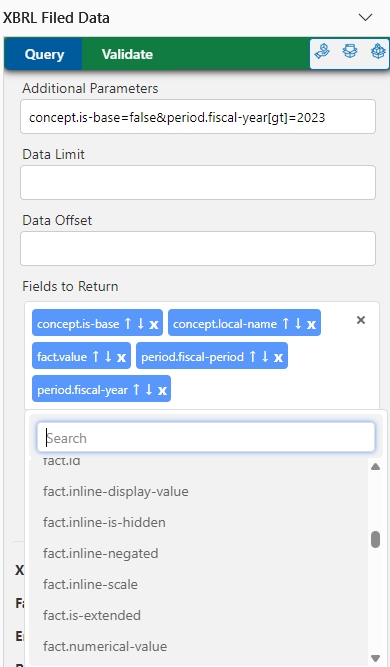 spreadsheet add-in's 'Additional Parameters' field and partial view of 'Fields to Return'
spreadsheet add-in's 'Additional Parameters' field and partial view of 'Fields to Return'https://api.xbrl.us/api/v1/fact/search?fields=concept.local-name,period.fiscal-year&
entity.code=0000789019&concept.is-base=false&
period.fiscal-year[gt]=2023
If you're using the XBRL Filed Data spreadsheet add-in for Excel or Google Sheets (see image at right), any valid filter parameter can be added to the 'Additional Parameters' text field (separated by an ampersand character - &). These add-ins also display the complete list of fields for the endpoint - just click the + in the 'Fields to Return' to see the list - making these tools a solid prototyping strategy for large-scale querying. A summary of updates to documentation is available on the documentation's GitHub repository We maintain a collection of free spreadsheet templates and code resources on the XBRL Data Community page.
Now we come to the payoff.
This updated filtering and enhanced functionality were also applied to our AI Connector. This LLM extension (known as an MCP or "model context protocol") returns standardized data from the XBRL US Public Filings Database for analysis and other AI tasks. The LLM loads the updated MCP tools into memory (one for each available XBRL API endpoint) when the application is started, and optimizes queries corresponding to user prompts. Functional enhancements have also been implemented that 1) expand the comparison logic, and 2) improve access to US GAAP taxonomy references:
- We initially used Anthropic's Claude to recommend how to enable comparison operators for
fact.valueandperiod.fiscal-year. The result led to an expanded application of comparison logic throughout the toolset, improving query efficiency and reducing token cost to get the right standardized data in AI tasks.As an example, try prompting with the MCP to 'create a list of all 10-K reports filed between April 1 and April 4 of the current year'. The earlier version of the MCP would query for as many reports as possible and filter results to fit the range; now the MCP applies the between operator to the report tool, filtering by filing date and returning only what was requested.
- Updating the references tool required more work, as FASB's Accounting Standards Codification (ASC) is returned as an array inside the concept object, making retrieval and alignment a bit more complex. Coupled with the expanded operator functionality, the references tool in the MCP can now surface concept differences across time: try prompting with the MCP to 'summarize changes to PropertyPlantAndEquipmentNet between US GAAP 2015 and US GAAP 2025'.
SEC APIs and EDGAR reports OR AI Connector MCP?
Let the task drive the decision.
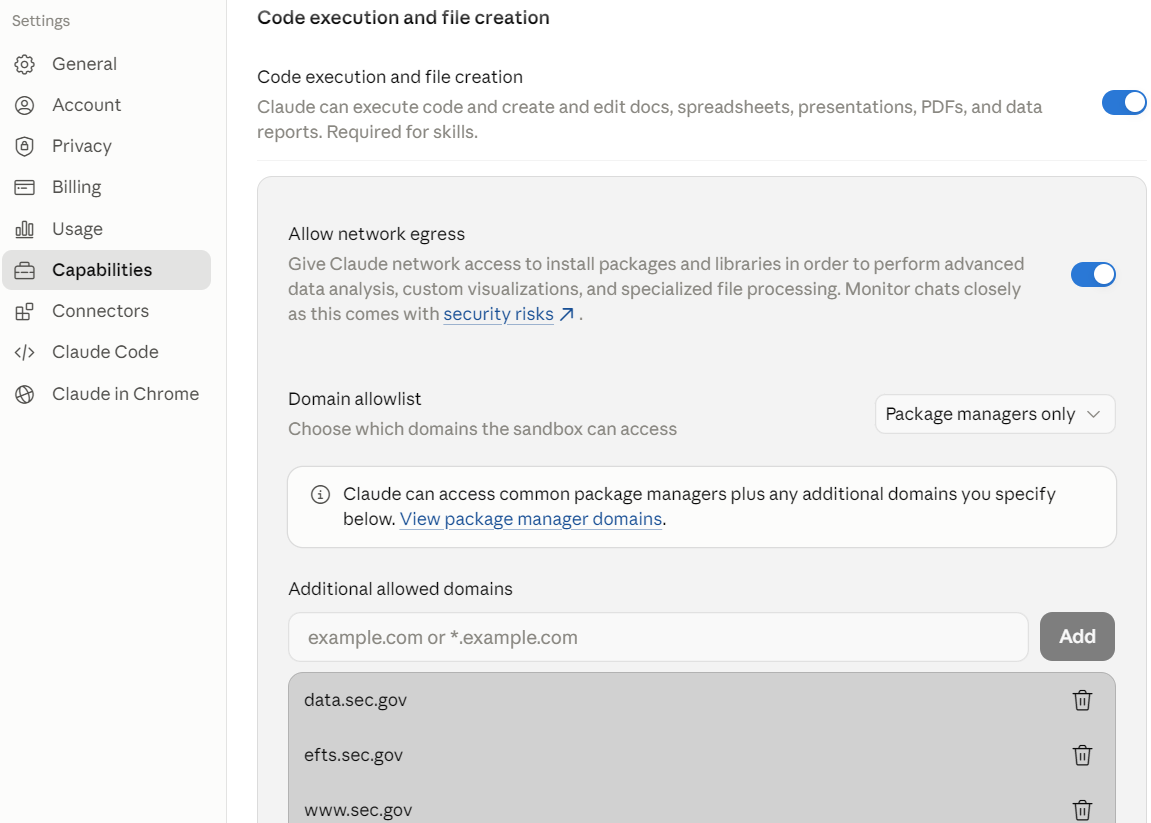 updating Claude to use the SEC's APIs
updating Claude to use the SEC's APIs While there are several open-source MCP tools available to query the SEC's APIs, getting data from the regulator natively with AI tools is becoming easier. For example, the default LLM in Microsoft's Copilot can connect directly to the SEC's APIs (althought it may iterate a bit to discover how to make the local machine's setup create supporting code for retrieval and display). Anthropic's Claude may require some configuration to allow SEC domains (see image at right), and without enabling this it will fall back to reading the Inline XBRL - these are positive and welcome developments in the push to make standardized source data available for AI tasks to avoid LLM hallucination and misinterpretation.
The differences in working with data using the SEC APIs and EDGAR or the XBRL US AI Connector are in breadth, scope and efficiency. The SEC APIs are very fast and work well for one company or concept at a time, while the AI Connector's comprehensive set of filtering options make gathering data for cross-company comparison at scale possible. The MCP also handles dimensions/axes natively; JSON from EDGAR requires additional processing to compile returned results. Finally, the MCP can access taxonomy metadata like concept labels and ASC mappings from the XBRL US Public Filings Database (although most LLMs have been trained with FASB's Codification).





Comment
You must be logged in to post a comment.