

By Marc Ward, Applications Manager, XBRL US
This blog is part of our ongoing series on how artificial intelligence reacts when working with structured, machine-readable (XBRL) data. See previous posts on J&J segment data and academic research comparing structured versus unstructured data as AI source.
Continuing our work leveraging the desktop version of Anthropic’s Claude LLM, we decided to test out how it works with energy-related data reported by public utilities to the Federal Energy Regulatory Commission (FERC). Since 2021, public utilities including electric, oil, natural gas, and services companies have been required to submit FERC eForms data, which includes financials and energy-related data, in structured format.
As with previous tests, we gave the LLM access to the XBRL US database of 15+ years of structured, machine-readable data through an MCP server (model context protocol). The database contains data sourced from Securities and Exchange Commission (SEC) filings, FERC filings, and ESEF (European Single Electronic Format) filings so it needed to distinguish between multiple XBRL sources.
In addition to changing the structured data source for the query, we also requested the LLM to compare findings for XBRL and non-XBRL sources in a single, consolidated prompt: “Please find quarterly megawatt hours sold for Puget Sound Energy, Inc. for 2023, 2024 and 2025 using XBRL data from the FERC Form 1 and FERC Form 3Q Electric and using non-XBRL data. Create a table comparing the data from both sources.”
We ran the query multiple times to see how results might vary. The first time we ran the prompt, Claude generated the table of key findings shown below. View the complete findings report here.
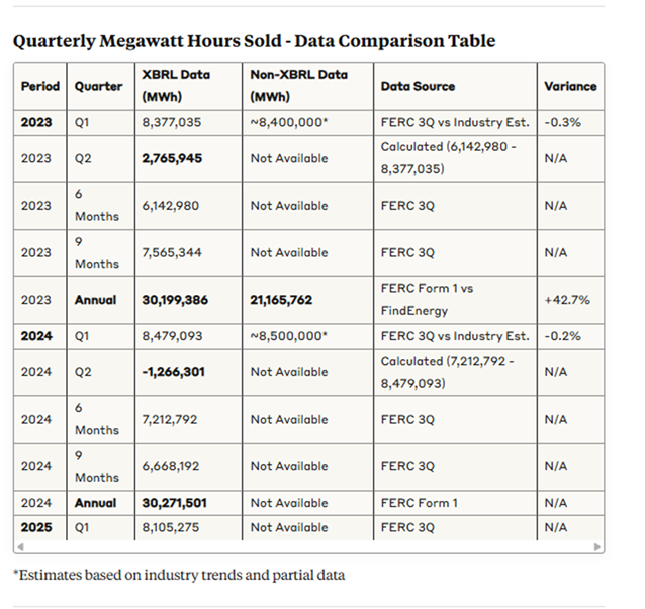
We checked the data reported for accuracy against Puget Sound Energy FERC filings and found that the XBRL-sourced data was accurate. The values reported from non-XBRL sources were incorrect for 2023; estimates that were provided for a few periods were close to the actual.
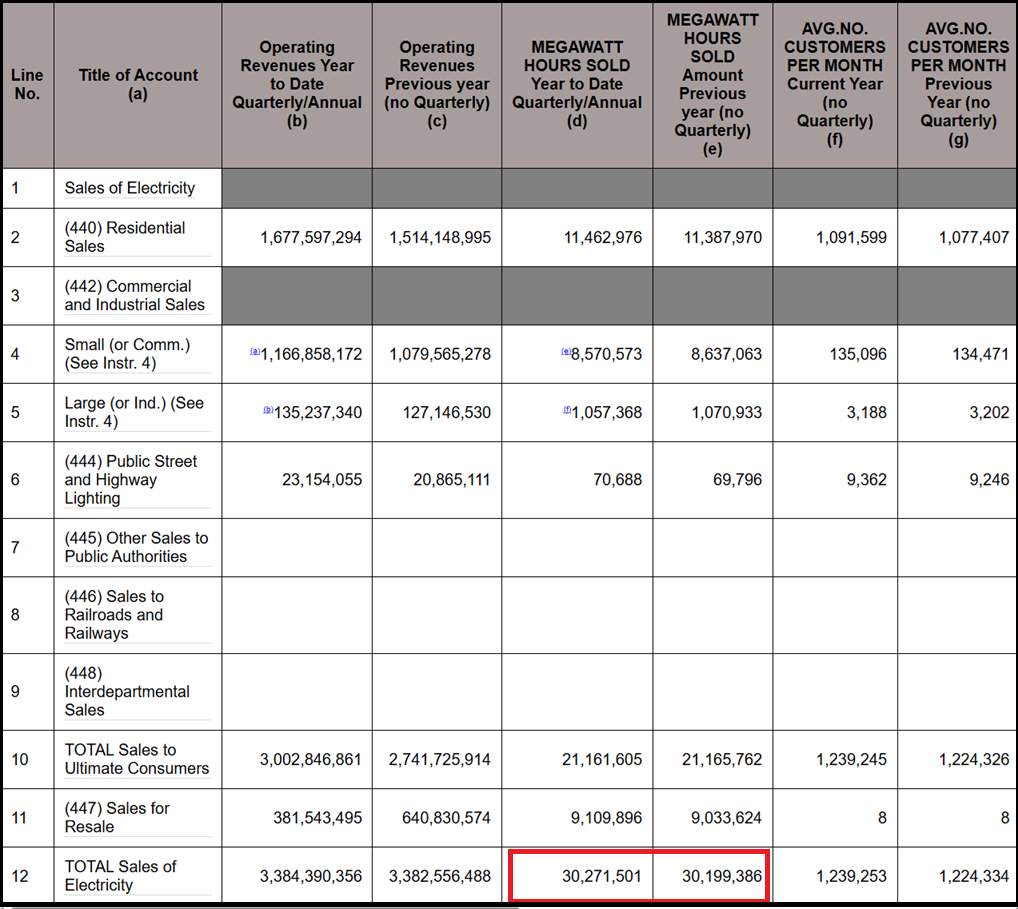
Below is a section of the company’s Form 1. The two values highlighted in red are the annual figures for 2023 and 2024 which match the AI response shown on the table above. To check other quarterly figures, use the FERC eCollections website.
The data generated from non-XBRL sources originated from Washington Utilities and Transportation Commission (UTC) Annual Reports, Third-party energy industry databases (FindEnergy.com), company press releases and regulatory filings and EIA (U.S. Energy Information Administration) government statistics.
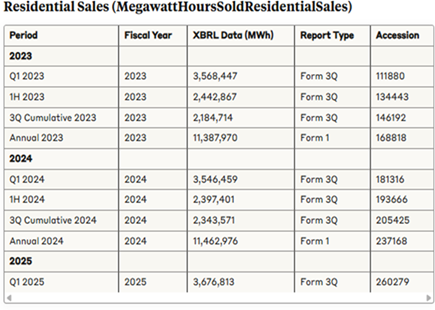
A subsequent attempt at the same prompt provided much more detailed XBRL data with megawatt hours sold broken down into residential, large/industrial and public street and highway lighting (residential is shown below, other tables can be found in the LLM detailed finding report here). Again, the XBRL-sourced data reported matched the company's FERC filings. This time, however, the LLM was unable to find any data in non-XBRL sources. Reasons cited by the LLM included limited public access, differences in data format (PDF or paper is harder to search systematically), and difficulty accessing historical archives.
Our key takeaways?
The XBRL sourced results were more accurate, consistent, authoritative and complete than data generated from unstructured sources.
We also found it curious that the LLM produced inconsistent responses through time. The same query, asked at different times or with a slight difference in prompt wording (for example, breaking a query into two sentences versus one sentence), gave different results. The inconsistency is a function of the randomness in the AI process but is important to consider when extracting financial data for analysis.
Regardless, AI is a powerful and useful tool, and we intend to keep testing, trying out different LLMs and running additional prompt tests. Stay tuned!




