

UPC codes. Shipping containers. Most people understand that the introduction of these kinds of standards revolutionized an existing process, making it better, faster, cheaper, by establishing a single method of doing something that is used by many. UPC codes made it possible to track purchasing habits worldwide. Shipping containers dramatically reduced the cost and time involved in shipping goods cross-country. Financial data standards can be similarly revolutionary - reducing processing costs, enabling automation and greater timeliness, providing for validation checks to improve accuracy.
There are different kinds of data standards. Some standards are open. Some are proprietary. An open standard is free and has no licensing fees associated with its use. Often there is confusion around what constitutes a financial data standard so we thought it would be worthwhile to break a standard down into its components.
A financial data standard has three components: format, information and identifiers. Accurate, consistent representation of financial data is only possible when all three components are combined. View an infographic depicting these three components.
Format
Today, companies report data to regulators in a multitude of formats, including PDF, Excel, CSV, XML, direct database entry into custom databases, JSON, etc. The format is the syntactical means used to structure and communicate the data. A data user receiving information in different formats must use different methods to extract and use it, often interpreting and translating the data first which requires human intervention and eliminates the ability to automate data processing.
The XBRL specification defines how data is captured and represented in an XBRL format. It was historically based on the XML format because of XML's ability to "tag" data with labels, rendering it computer-readable. XBRL International, which maintains the XBRL technical specification, is now expanding the specification to allow tagged data to be captured and represented in other formats like JSON, CSV and standard database schemas.
Information
Descriptive metadata that gives context to reported facts so they can be understood by creators and users of the data, is contained in the Information component. To accurately represent financial data, metadata should include:
- Data fields including labels and definitions
- Units, e.g., currency, volume or power measures
- Scale, e.g., the data is represented in millions or thousands
- Disaggregation, e.g., breakdown of revenue or gross profit by business unit or geography
- Time period
- Reporting entity
In the XBRL standard, data fields and other descriptive information such as labels and definitions, are collected in a digital dictionary called a taxonomy which can be based on an existing standard like US GAAP, UK GAAP or ISO 20022 for corporate actions messages. The information component relies on taxonomy structure to convey data labels and definitions; it relies on the XBRL International Units Registry to contain consistent units metadata; and the XBRL technical specification to provide persistent methods to describe scale, time period (represented through the ISO 8601 standard) and disaggregation of data into business unit, geography or other categorizations that a company may need. The specification also provides links to identification standards that are important to fully understand the financial data provided such as identifiers for reporting entity or industry classification. For SEC reporting, XBRL provides a method so that companies can use the SECs approved reporting entity identifier - the Central Index Key (CIK).
Companies that report using the same descriptive metadata standard can not only be easily compared, but their data can be extracted and analyzed using the same software applications.
Identifiers
The Identifier component contains standard identifiers to describe information such as reporting entity, security, security product and industry classification. There are multiple standards for some of these identifiers. For example, to distinguish legal reporting entity, different government agencies often rely on different identifiers, some open and some proprietary. The SEC uses the Central Index Key (CIK) to identify public companies; other agencies have adopted the Legal Entity Identifier (LEI), which is a global entity identifier; some agencies use the Employer Identification Number (EIN), and still others rely on proprietary formats such as CUSIP (Committee on Uniform Security Identification Procedures).
Other forms of classification where disparate standards exist include:
- Security Identifier, e.g., Bloomberg id, CUSIP, ISIN, SEDOL
- Security Product Identifier, e.g., ISO-CFI, FIBO
- Industry (Product) Identifier, e.g., SIC, GICS, NAICS
It is important to leverage existing standard identifiers where they are available. Without the adoption of a single, standard identifier, data users must rely on mapping tables requiring significant maintenance and real-time updates that are unnecessarily manual, prohibitively expensive and prone to error. 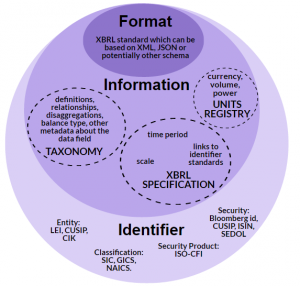
XBRL - the financial data standard
XBRL is the only data standard that contains all three components necessary to accurately and consistently represent financial data as shown in the diagram above. So if you are searching for a data standard that can accurately represent financial data, look no further. XBRL is transforming financial data reporting around the world because of the automation, consistency, and ultimately the cost savings that it can bring.
Read the white paper for more detail on financial data standards.




